그룹 함수란?
- 그룹 함수들은 집계 함수 (Aggregate function)이라고도 한다.
- 집계란 하나 이상의 데이터들을 대상으로 일종의 통계정보 (전체 개수, 평균, 최댓값, 최솟값)를 말하며
집계 함수 역시 이러한 기능을 수행하는 함수들을 말한다.
- 단일 행 함수와 달리 그룹 함수는 전체 집합 또는 그룹으로 분류된 집합에 작용하여 그룹당 하나의 결과를
생성한다.

여러 건의 데이터를 묶어서 동작하는 것이 그룹 함수다.라고 생각하자.
[그룹 함수의 종류]

널값인 값들을 모두 빼고 계산한다.
하지만 COUNT(*)함수만 NULL값을 포함한 행의 수를 출력합니다.
[그룹 함수 사용 지침]
- DISTINCT를 지정하면 함수는 중복되지 않는 값만 검토하고, ALL을 지정하면 중복값을 포함한 값을 검토함
- ALL 키워드는 기본값이므로 별도로 사용할 필요가 없음
- Count(*)를 제외한 모든 그룹 함수는 Null 값을 제외하고 처리함
- Null 값을 특정 값으로 치환하려면 NVL 함수를 사용함
- 모든 데이터 타입에 MIN, MAX, COUNT함수를 사용할 수 있음
(날짜는 과거로 갈수록 작은 값, 최근으로 올수록 큰 값이다. 즉, 최근 날짜 조회 시 MAX 사용하면 된다.)
(문자 데이터에 관해서도 MIN, MAX사용 가능하다.)
- AVG, SUM, VARIANCE, STDDEV는 숫자 데이터 타입만 사용이 가능함 (문자 데이터는 사용 불가)

문자 날짜에 대해서 MIN, MAX사용 가능하다.

업무가 SALESMAN인 애들만 평균이 얼마인지 최소 급여가 얼마인지, 최대 급여가 얼마인지, 합계는 얼마인 지조회

LOWER함수를 사용한 것은 한줄한줄 모든 결과값이 소문자로 바꿔서 출력
아래의 MIN함수를 사용한 것은, 그룹으로 묶어서 결괏값이 하나만 출력되어 조회되는 것을 확인할 수 있습니다.
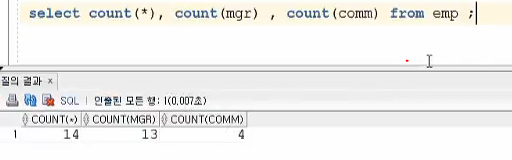
COUNT(*) : null이 있던 말던 신경 쓰지 말고 총데이터의 값은 몇 건 인지 확인
COUNT(mgr) : mgr에서 null인 값은 뺀 개수
COUNT(comm) : comm에 null인 값은 뺀 개수

결과 1 : null인 애들은 빼고 null이 아닌 애들만 보너스 계산해서 평균값 구하기
결과 2 : 보너스에 널로 된 값은 0으로 바꾼 후의 평균값 구하기
GROUP BY 절
- 테이블의 행을 더 작은 그룹으로 나눔
- 집계 함수 이외에 SELECT 절에 나오는 칼럼이나 값은 두 GROUP BY절에 명시함(상수 값 제외)
- 한 개 이상의 칼럼이나 값이 올 수 있음 (여러개 컬럼 가능)
- GROUP BY 절을 이요하여 그룹으로 묶은 후 SELECT절에는 GROUP BY에서 사용한 <속성>과 집계 함수만 나올 수 있음.
- WEHRE 조건 절에 사용된 컬럼이나 값은 GROUP BY절에 사용한 컬럼이나 값과 달라도 상관없음
- WHERE 조건이 먼저 처리된 후 GROUP BY 집계 함수가 처리됨
- ORDER BY 절을 사용하면 그룹핑한 결과를 일정한 순서로 볼 수 있음
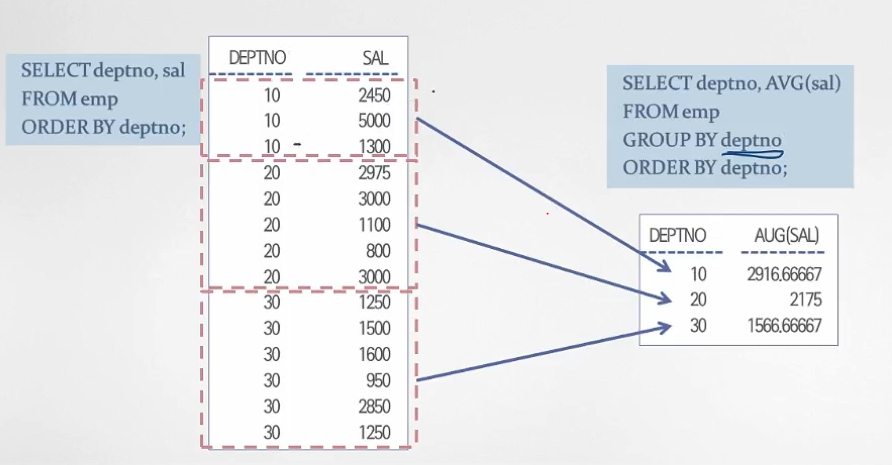
Group By절의 사용

Group By기준을 2개로 주어도 된다. 업무와 부서 기준으로 분류하여 부서 번호, 업무, 인원수, 급여의 평균, 급여합 조회
(ex) job, deptno

position이 DF인 선수들이 각 팀에 몇 명이 있는지 인원수 조회

보통 Group By절에 칼럼은 Select절에 같이 사용됩니다. 의미 있게 정보 확인이 가능하다.
HAVING절 사용
예를 들어 합계금액이 1억이 넘는 지점만 보고 싶다. 이럴 때 그룹 함수를 이요한 조건을 사용할 때 HAVING 절을 사용해주면 된다.
- Group By절의 기준 항목이나 소그룹의 집계 함수를 이용한 조건을 표시할 수 있음
- WHERE 절은 Aggregation 이전, HAVING 절은 Aggregation 이후의 filtering 작업을 수행한다.
- Group By절에 의해 소그룹 별로 만들어진 집계 데이터 중, HAVING 절에서 제한 조건을 두어 조건을 만족하는 내용만 출력한다.
- 그룹이 형성되고, 그룹 함수가 계산된 후 HAVING절이 적용됨
* 행이 분류됨(그룹 형성)
* 그룹 함수가 그룹에 적용됨
* HAVING절의 조건에 일치하는 그룹이 표시됨.

GROUP BY절까지만 본다면, 부서가 100개라면 100개의 데이터가 300개면 300개의 데이터가 나올 것이다.
하지만, HAVING 절에 평균이 2000이 넘는 것만 조회할 것이다.

각 팀의 평균 몸무게를 보는데 73 넘는 것만 보고 싶을 때

WHERE절에 그룹 함수를 이용한 조건을 써주면 무조건 에러 발생
기준이 없기 때문이다. AVG, MIN, MAX, SUM 사용 불가.
예제)
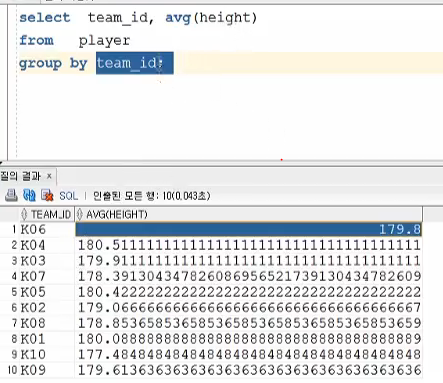
team_id별로 그룹을 묶어서 평균을 확인할 수 있다.

group by 절로 묶은 것의 조건을 HAVING 절로 주어 평균이 180 이상인 팀만 조회 가능하다.
추가적으로 정렬해서 보고 싶을 땐 맨 마지막에 order by team_id를 붙여주면
정렬된 순서로 조회 가능합니다.
마지막 정리
( MAX, MIN, Count함수는 문자, 숫자, 날짜 모두 사용할 수 있다.)
(숫자 : MAX, MIN, AVG, SUM..)
각 부서별 평균 급여를 조회는 문장
SELECT DEPTNO, AVG(SAL)
FROM EMP
GROUP BY DEPTNO;
실행 순서는 WHERE -> GROUP BY -> HAVING절 순서로 처리된다.
'데이터베이스 > 기초 SQL 입문' 카테고리의 다른 글
| 조인 처리과정 이해 및 기본 조인 문장 (0) | 2020.09.16 |
|---|---|
| 윈도우 함수 (0) | 2020.09.16 |
| 일반 함수 (0) | 2020.09.13 |
| 변환 함수 (0) | 2020.09.13 |
| 날짜 연산 및 날짜 함수 (0) | 2020.09.11 |



